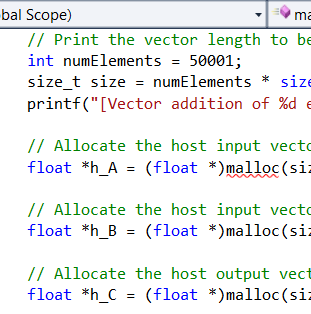
The NVIDIA CUDA SDK Example shows how to do an extremely simple vector addition in CUDA using the following kernel:
__global__ void
vectorAdd(const float *A, const float *B, float *C, int numElements)
{
int i = blockDim.x * blockIdx.x + threadIdx.x;
if (i < numElements)
{
C[i] = A[i] + B[i];
}
}
Three blocks of memory are allocated on the card: the two source vectors and a destination vector. The kernel is then launched with 256 threads per block and as many blocks as necessary to cover the vector.
int threadsPerBlock = 256;
int blocksPerGrid =(numElements + threadsPerBlock - 1) / threadsPerBlock;
printf("CUDA kernel launch with %d blocks of %d threads\n", blocksPerGrid, threadsPerBlock);
vectorAdd<<<blocksPerGrid, threadsPerBlock>>>(d_A, d_B, d_C, numElements);
Note that if the vector is not a multiple of 256 then the if statement in the kernel will prevent adding items beyond the end. At the time of this writing (Jan 2015 on CUDA 6.5) the behavior will be that a branch in the code will first execute the kernels that execute TRUE and then all kernels that execute the FALSE branch. Since the FALSE branch is null, this is quite simple. However, it is still something to watch for.
The output is as follows:
[Vector addition of 50001 elements] Copy input data from the host memory to the CUDA device CUDA kernel launch with 196 blocks of 256 threads Copy output data from the CUDA device to the host memory Test PASSED Done Press any key to continue . . .