Example Path: %NVCUDASAMPLES_ROOT%\1_Utilities\deviceQueryDrv
The NVIDIA CUDA Example Device Query shows how to discovery GPGPU’s on the host and how to discover their capabilities.
The basic execution looks like the following for a Geforce GT650M card in an HP Pavilion dv6 Laptop:
deviceQuery.exe Starting...
CUDA Device Query (Runtime API) version (CUDART static linking)
Detected 1 CUDA Capable device(s)
Device 0: "GeForce GT 650M"
CUDA Driver Version / Runtime Version 6.5 / 6.5
CUDA Capability Major/Minor version number: 3.0
Total amount of global memory: 1024 MBytes (1073741824 bytes)
( 2) Multiprocessors, (192) CUDA Cores/MP: 384 CUDA Cores
GPU Clock rate: 835 MHz (0.83 GHz)
Memory Clock rate: 2000 Mhz
Memory Bus Width: 128-bit
L2 Cache Size: 262144 bytes
Maximum Texture Dimension Size (x,y,z) 1D=(65536), 2D=(65536, 65536),
3D=(4096, 4096, 4096)
Maximum Layered 1D Texture Size, (num) layers 1D=(16384), 2048 layers
Maximum Layered 2D Texture Size, (num) layers 2D=(16384, 16384), 2048 layers
Total amount of constant memory: 65536 bytes
Total amount of shared memory per block: 49152 bytes
Total number of registers available per block: 65536
Warp size: 32
Maximum number of threads per multiprocessor: 2048
Maximum number of threads per block: 1024
Max dimension size of a thread block (x,y,z): (1024, 1024, 64)
Max dimension size of a grid size (x,y,z): (2147483647, 65535, 65535)
Maximum memory pitch: 2147483647 bytes
Texture alignment: 512 bytes
Concurrent copy and kernel execution: Yes with 1 copy engine(s)
Run time limit on kernels: Yes
Integrated GPU sharing Host Memory: No
Support host page-locked memory mapping: Yes
Alignment requirement for Surfaces: Yes
Device has ECC support: Disabled
CUDA Device Driver Mode (TCC or WDDM): WDDM (Windows Display Driver Mo
del)
Device supports Unified Addressing (UVA): Yes
Device PCI Bus ID / PCI location ID: 1 / 0
Compute Mode:
< Default (multiple host threads can use ::cudaSetDevice() with device simu ltaneously) >
deviceQuery, CUDA Driver = CUDART, CUDA Driver Version = 6.5, CUDA Runtime Versi
on = 6.5, NumDevs = 1, Device0 = GeForce GT 650M
Result = PASS
The example first discovers the number of devices using cuDeviceGetCount(..) and then iterates over g a host of capability discovery functions such as:
- cuDriverGetVersion(…)
- cuDeviceTotalMem(…)
- getCudaAttribute(…)
Where the bulk of the attributes are retrieved with getCudaAttribute using an enumerated selector to return the right value as in:
int asyncEngineCount;
getCudaAttribute<int>(&asyncEngineCount, CU_DEVICE_ATTRIBUTE_ASYNC_ENGINE_COUNT, dev);
And if there are more than two devices it checks to see if RDMA is enabled between them.
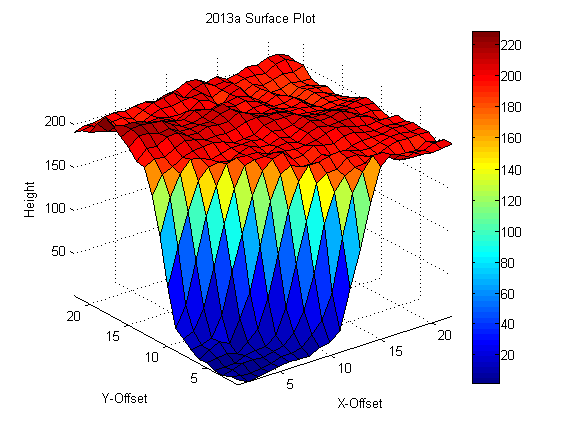
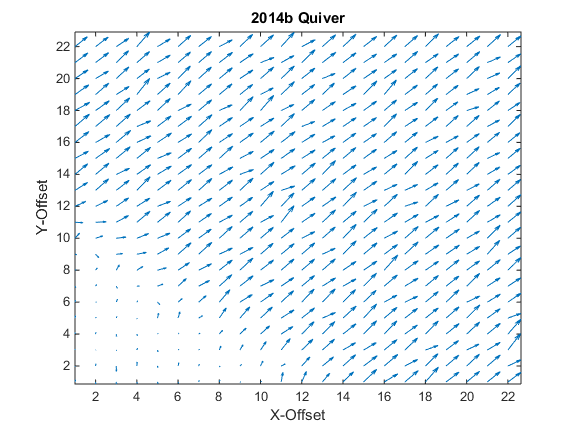
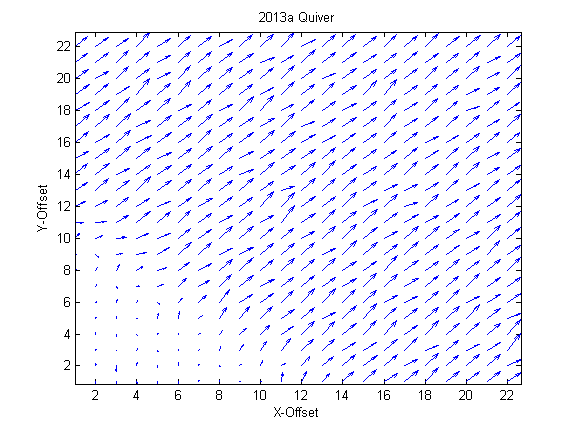
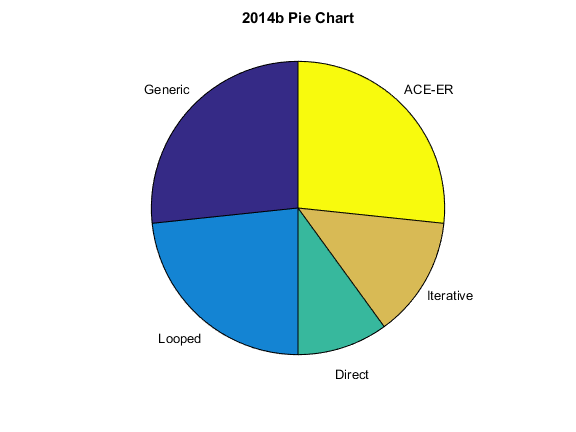

{kind=link}