Presentation on Turbulence Mitigation using low rank estimation.
Download: Robust Subspace Estimation Using Low-Rank Optimization
 .
.
Development, Research, Other Stuff

Presentation on Turbulence Mitigation using low rank estimation.
Download: Robust Subspace Estimation Using Low-Rank Optimization
.
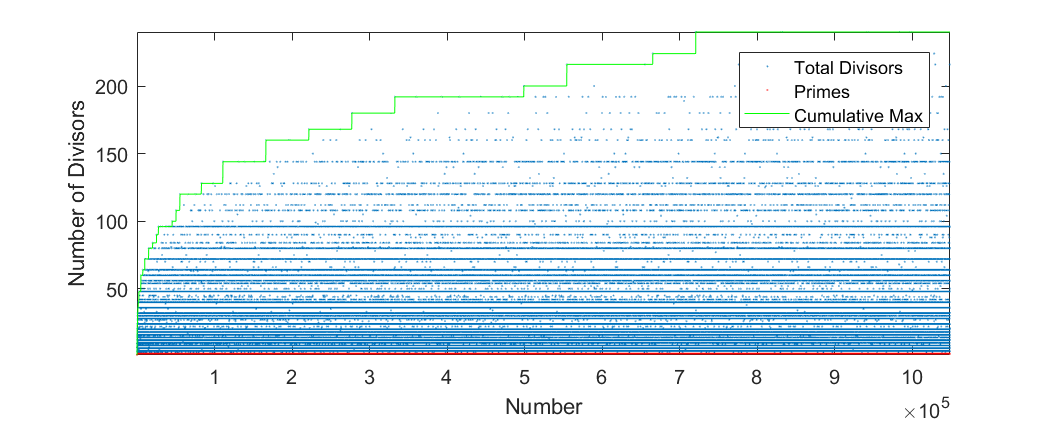
A fun video of highly composite numbers:
And a plot from MATLAB displaying increasing numbers and their number of divisors up to 2^20.
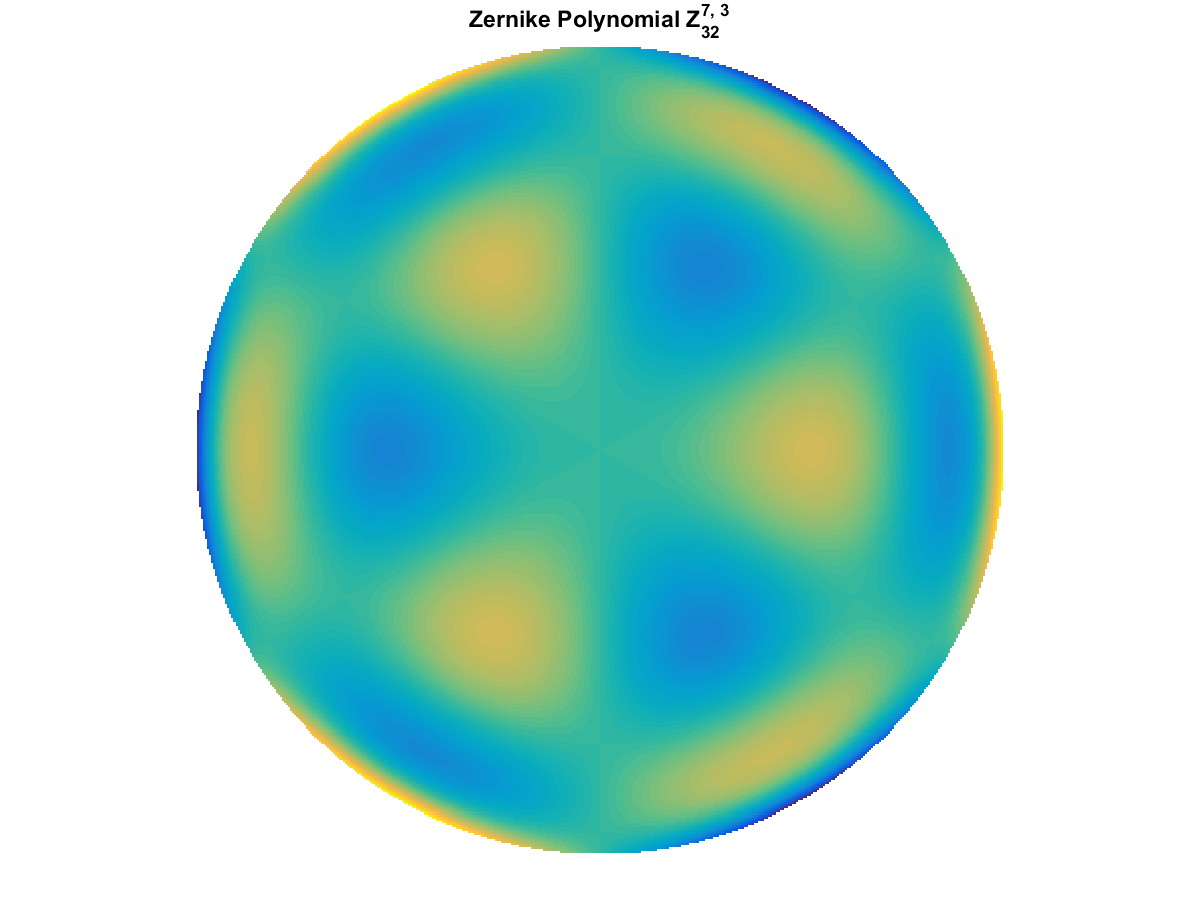
A quick implementation of of Zernike polynomials for modeling wavefront aberrations to to optical turbulence. Equations pulled from Michael Roggemann’s Imaging Through Turbulence.
Zernike polynomials are often used to model wavefront aberrations for various optics problems. The equations are expressed in polar coordinates, so to calculate the image we first convert a grid into polar coordinates using the relation
\(y = r\times sin(\theta) \)
\(r = \sqrt{x^2 + y^2} \)
\(\theta = tan^{-1}\frac{y}{x}\)
And then calculate the Zernike Polynomials as
\(Z_{i,even}(r,\theta) = \sqrt{n+1}R^m_n(r)cos(m\theta) \)
\(Z_{i,odd}(r,\theta) = \sqrt{n+1}R^m_n(r)sin(m\theta) \)
and \(Z_{i}(r,\theta) =R^0_n(r)\) if \(m=0\)
Where the functions \(R^m_n(r)\) are called Radial Functions are are calculated as
\(R^m_n(r) =\sum_{s=0}^{(n-m)/2} \frac{(-1)^s(n-s)!}{s![(n+m)/2 – s]![(n-m)/2 – s]!} r^{n-2s} \)
With Noll normalization. Certain polynomials have names. First is \(Z_1\), know as Piston as is often subtracted to study of single aperture systems. Next, \(Z_2\) and \(Z_3\) are ramps that are called tilt and cause displacement. \(Z_4\) is a centered ring structure known as defocus while \(Z_5\) and \(Z_6\) are astigmatism, \(Z_7\) and \(Z_8\) are coma, and \(Z_{11}\) is spherical aberration.
They can be imaged as follows:
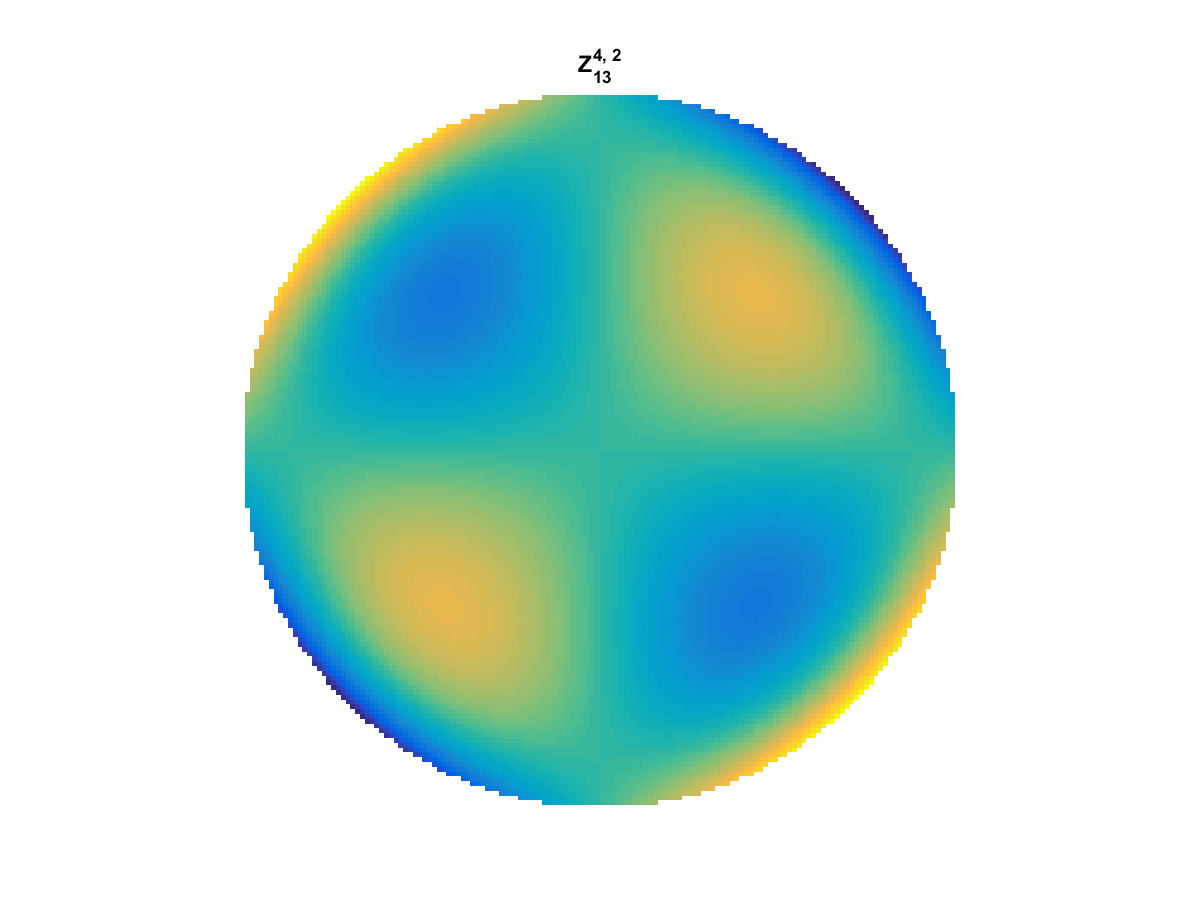
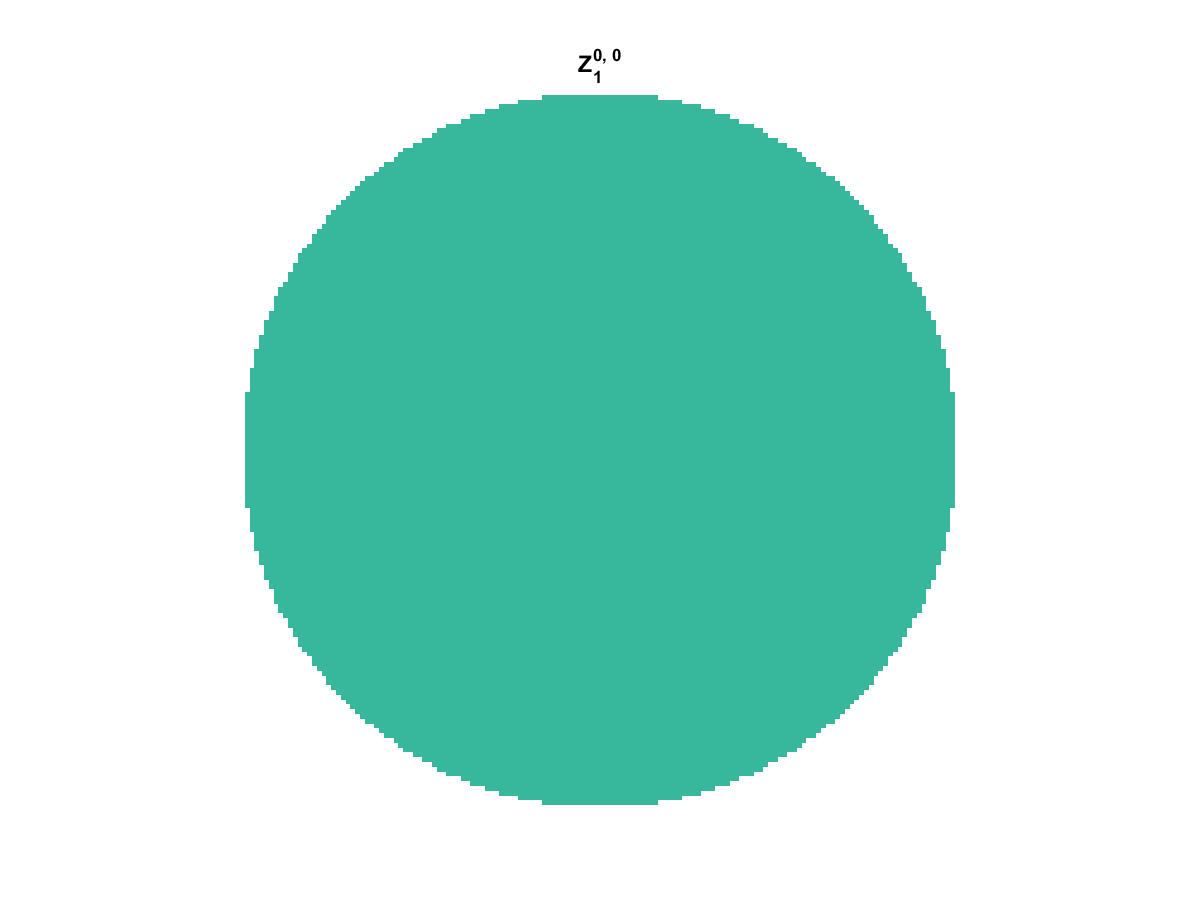
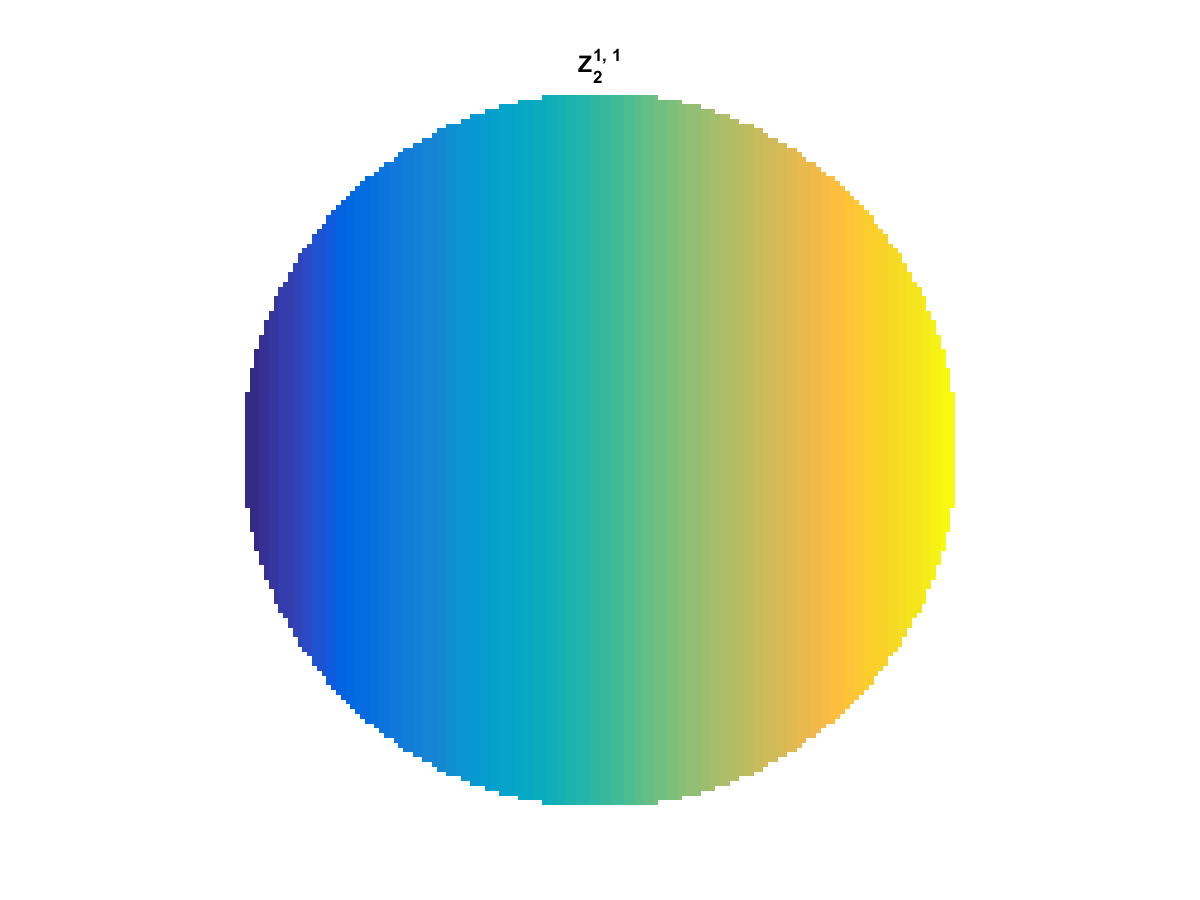
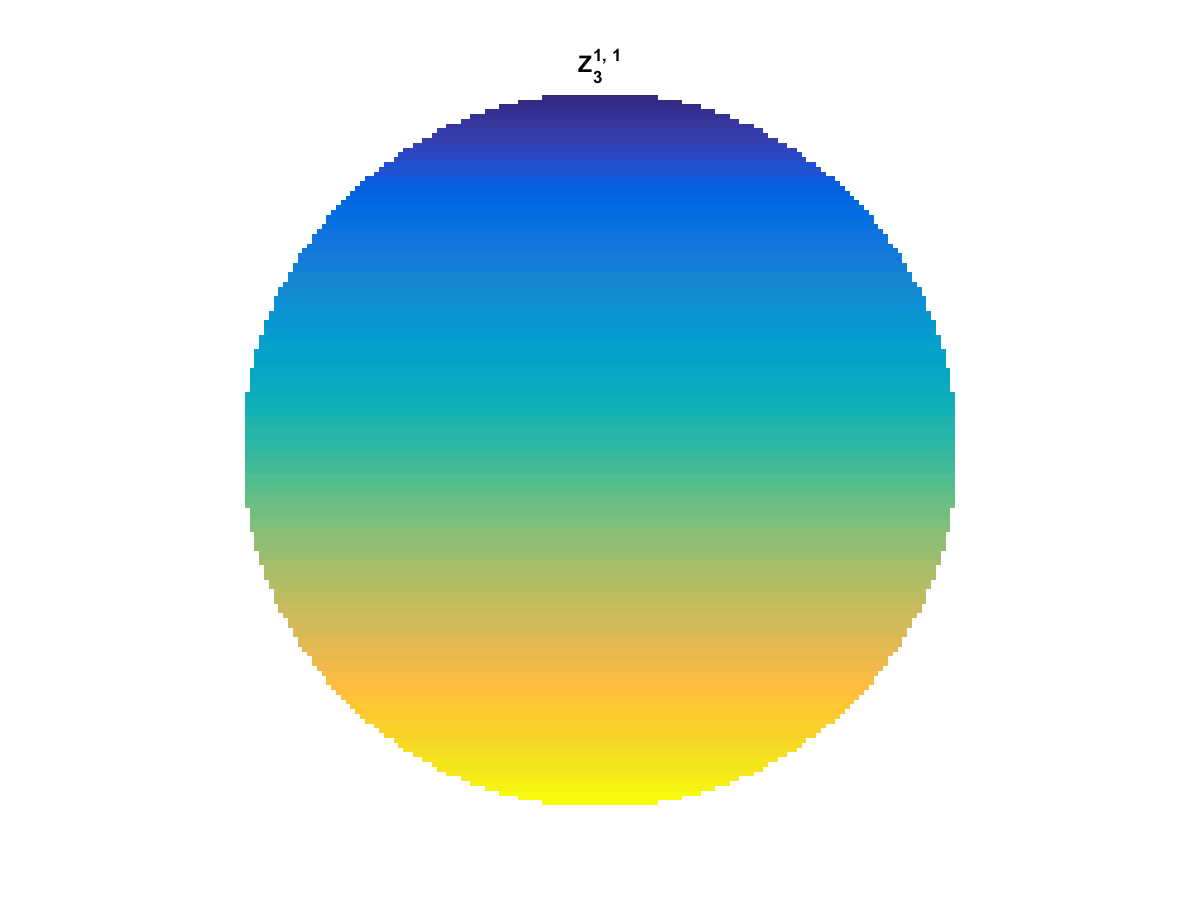
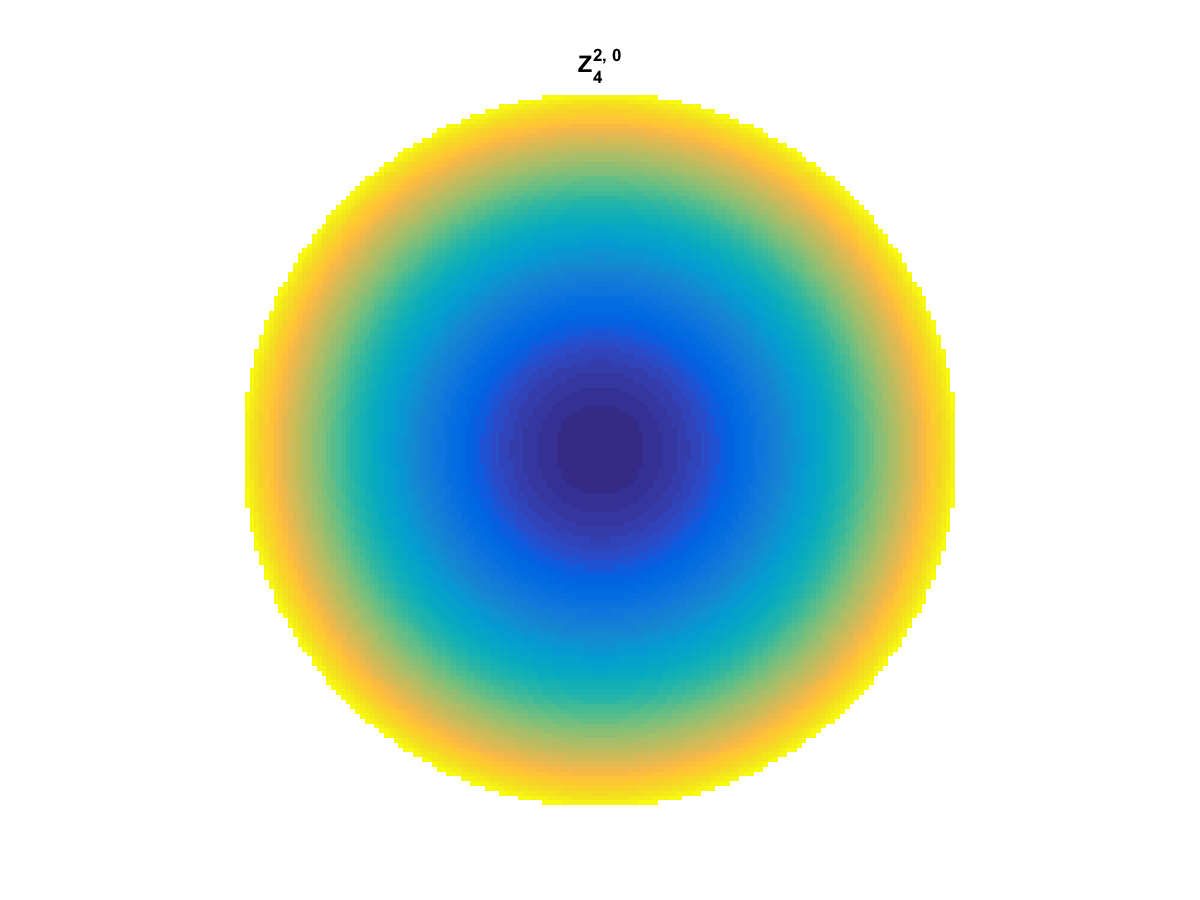
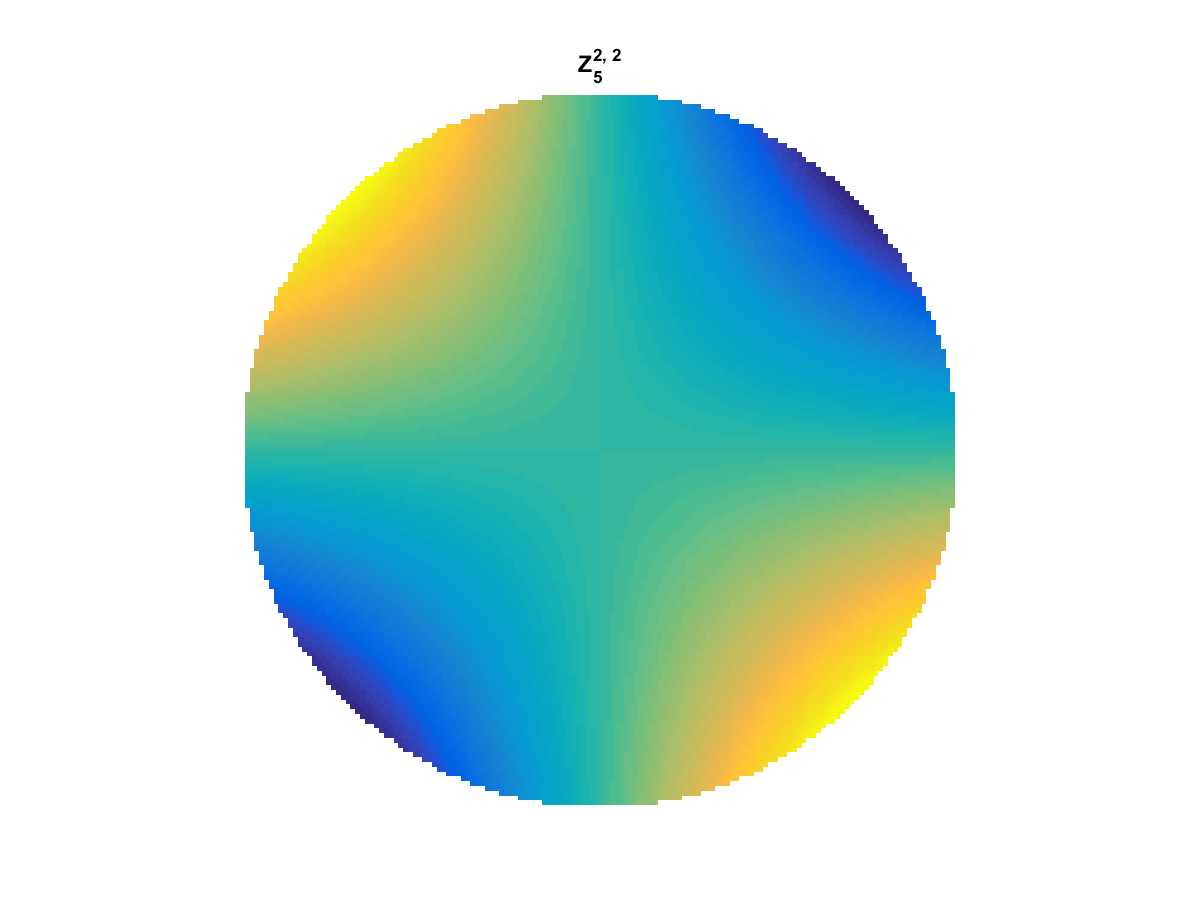
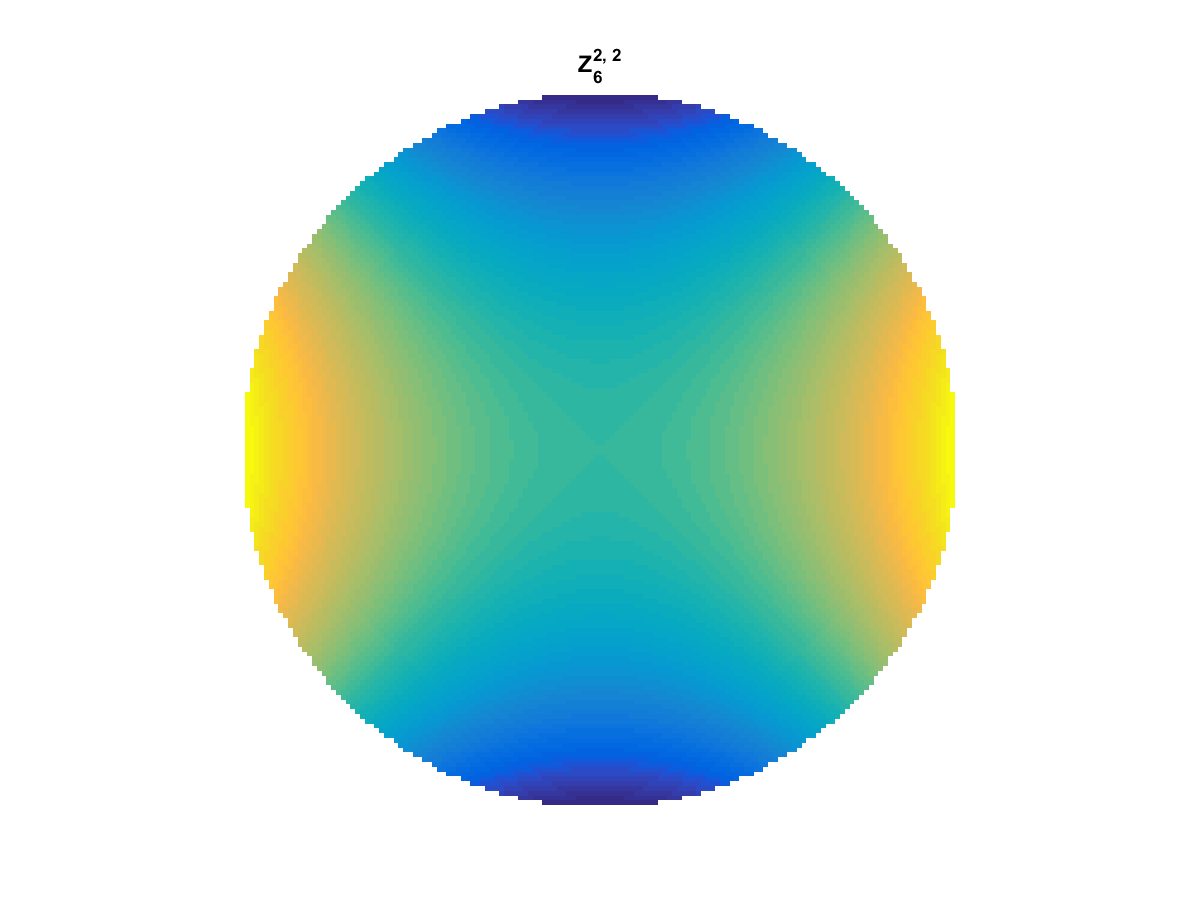
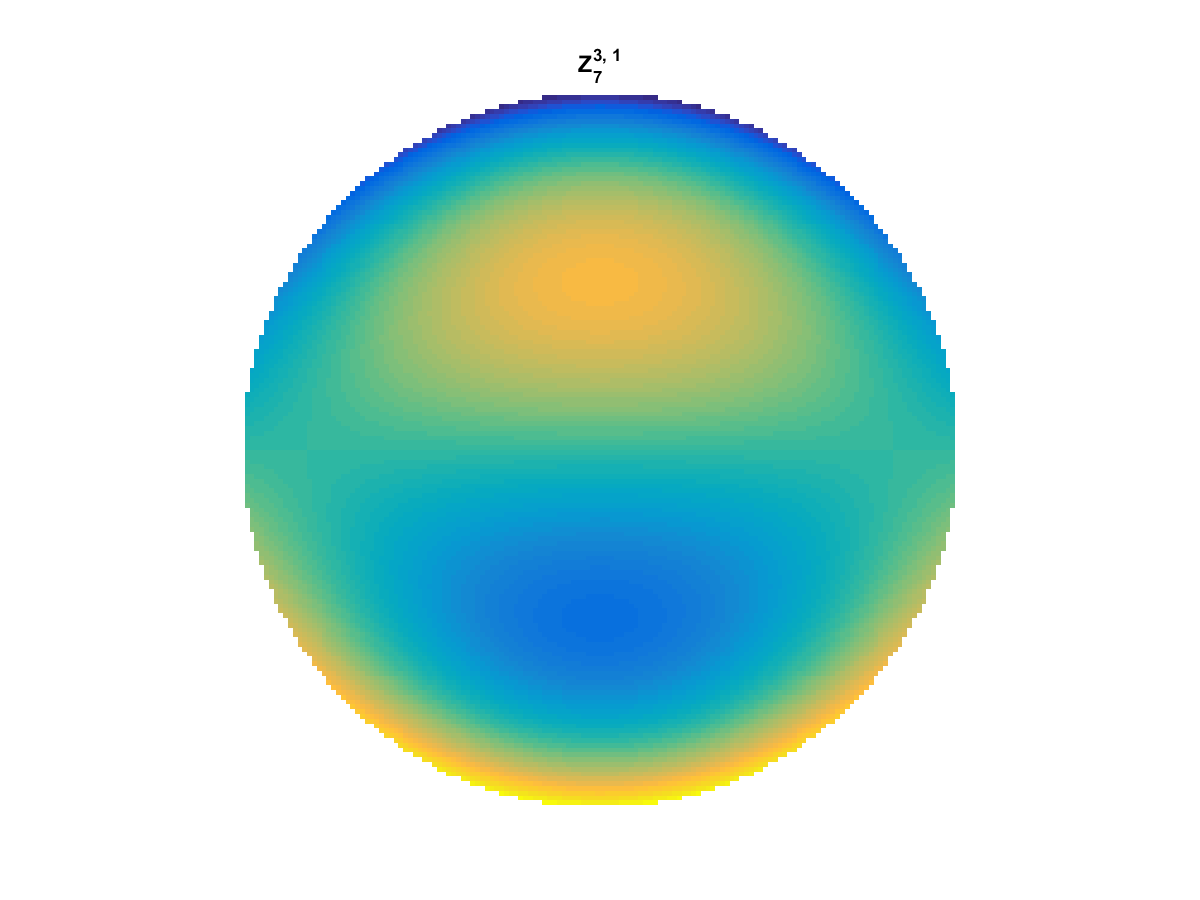
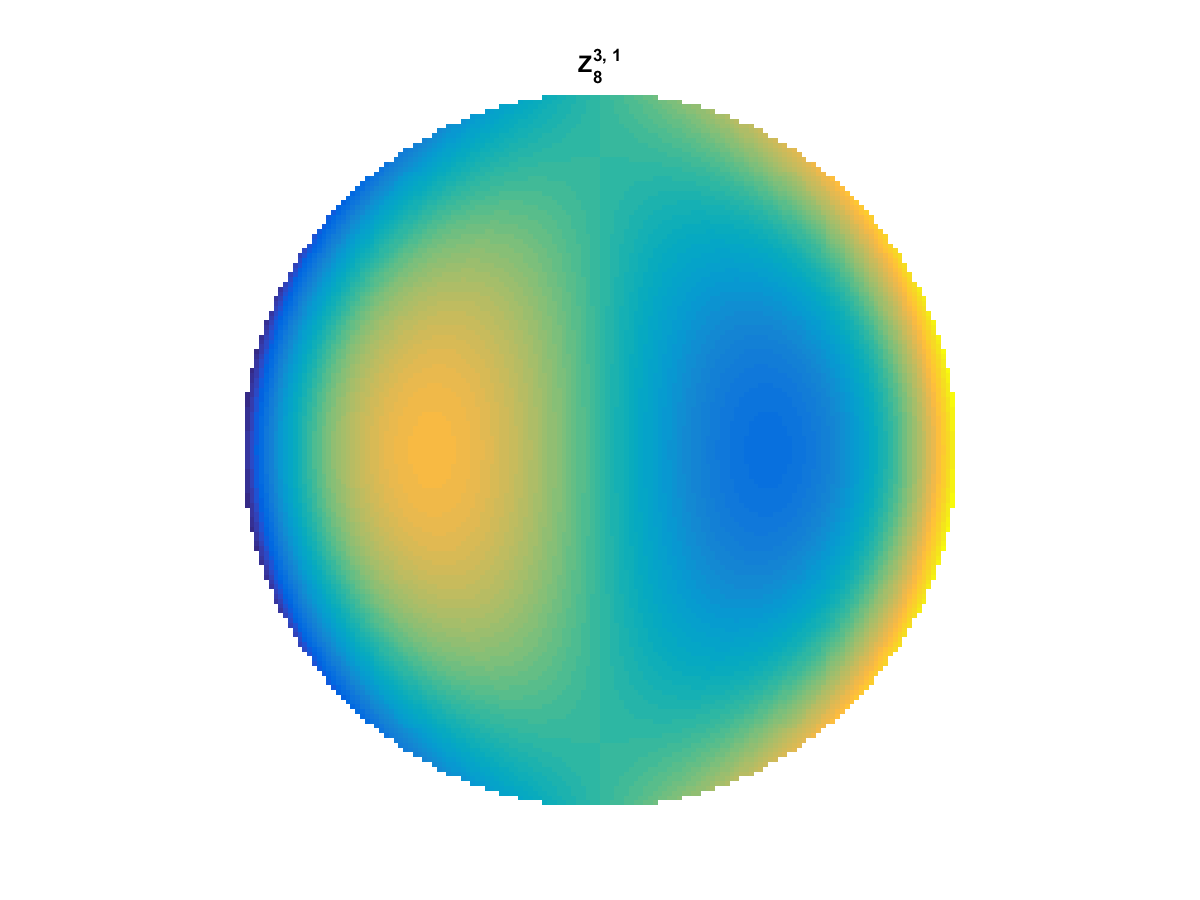
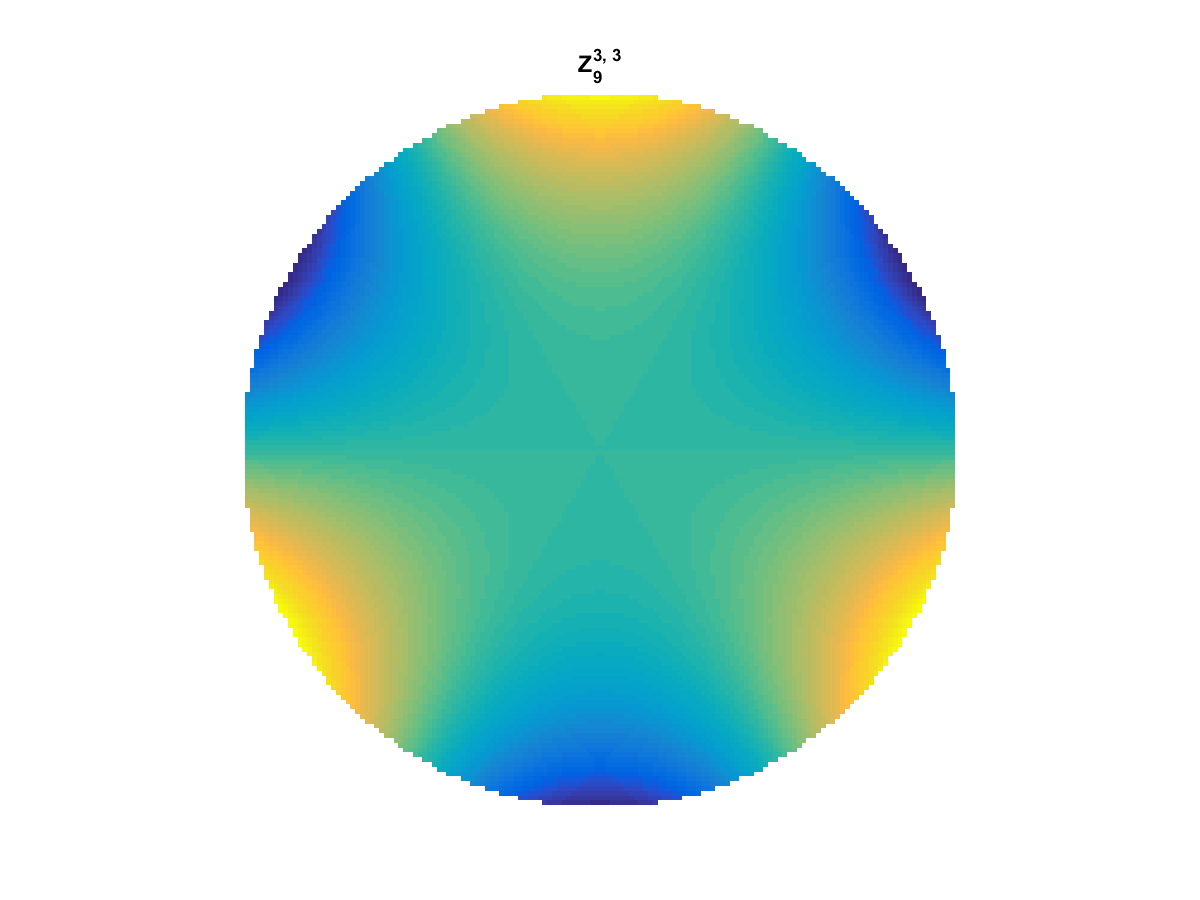
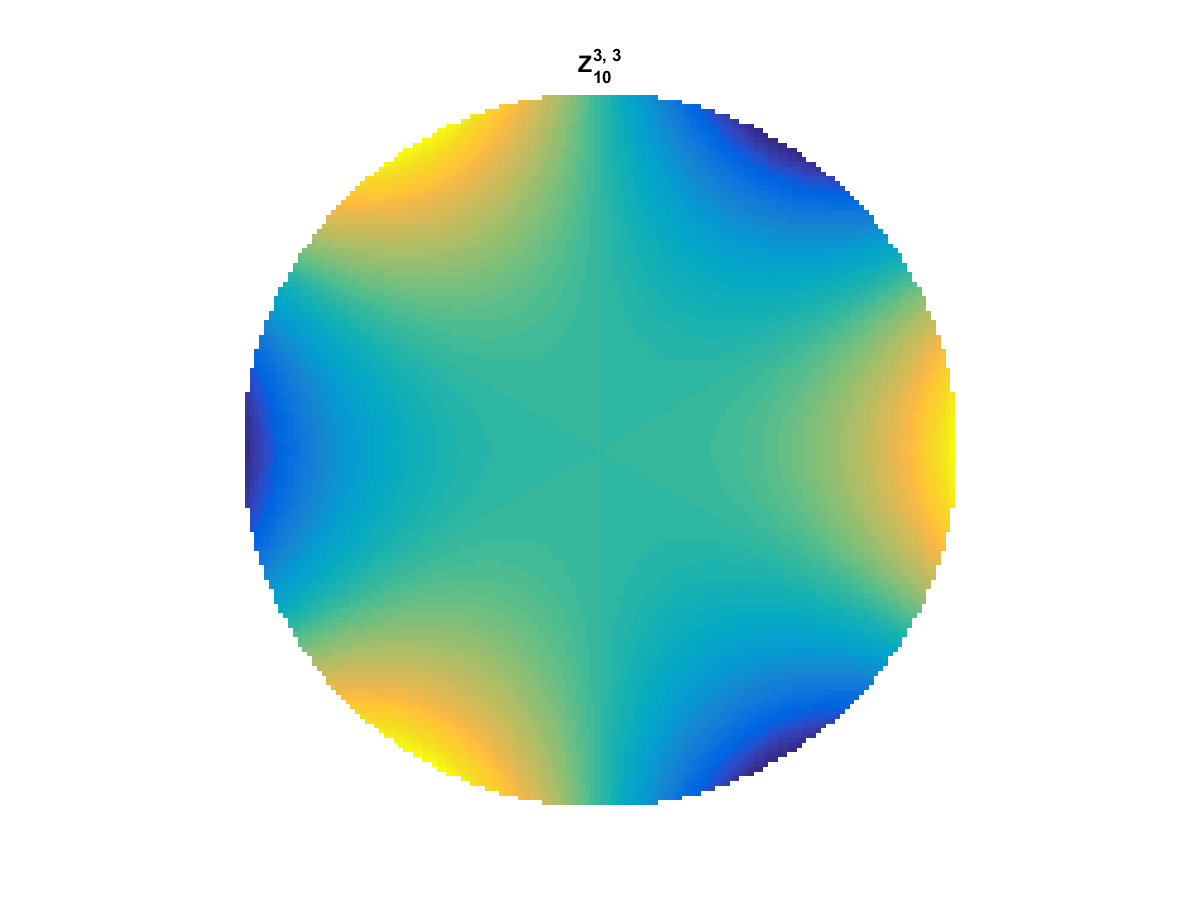

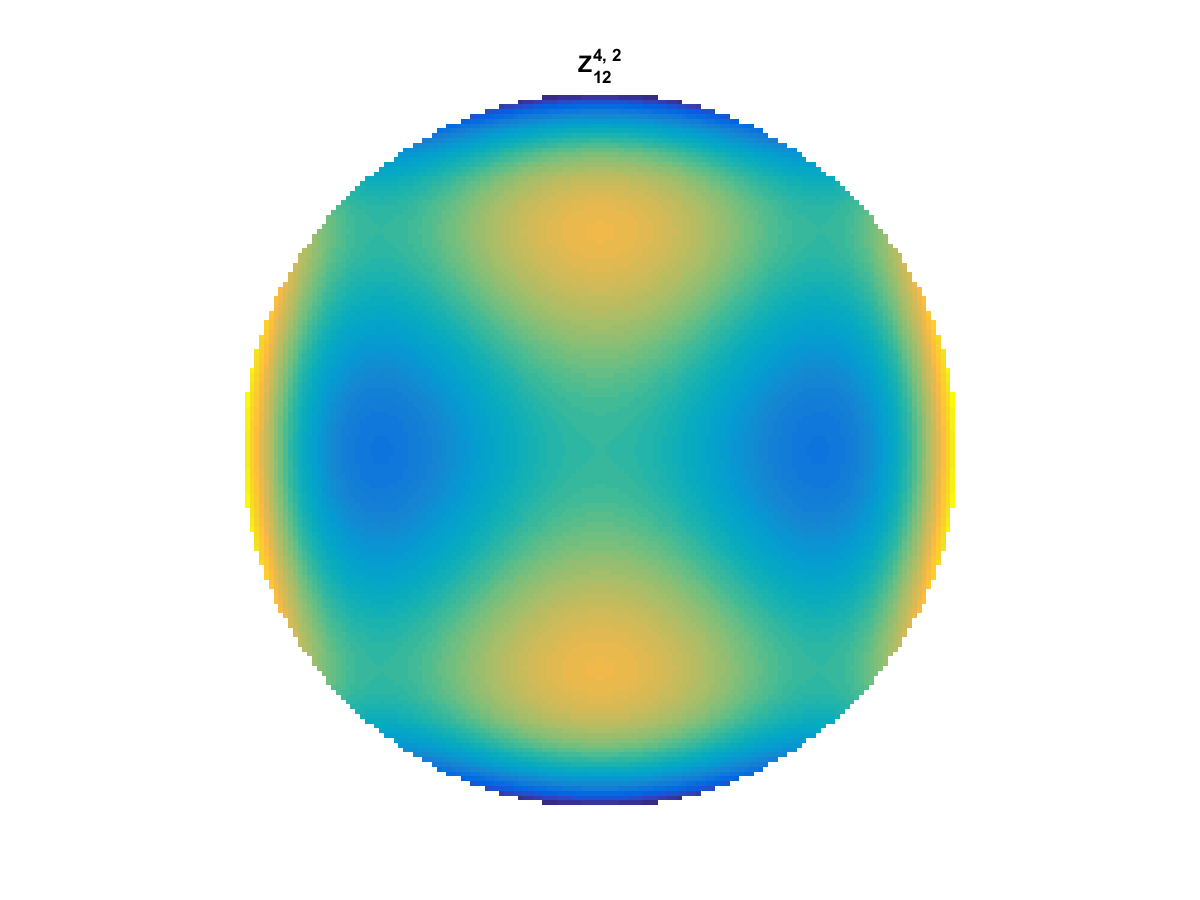
All created using the following code:
function result = z_cart(i,m,n, x,y) %Z_POL result the zernike polynomial specified in cartesian coordinates % calculate the polar coords of each point and use z_pol: r = (x.^2 + y.^2).^(1/2); thta = atan2(y,x); result = z_pol(i,m,n,r,thta); end function result = z_pol(i, m,n, r,t) %Z_POL result the zernike polynomial specified in polar coordinates if(m==0) result = radial_fun(0,n,r); else if mod(i,2) == 0 % is even term2 = cos(m*t); else term2 = sin(m*t); end result = sqrt(n+1)*radial_fun(m,n,r).*term2; end end function result = radial_fun(m,n,r) %RADIAL_FUN calculate the radial function values for m,n, and r specified result = 0; for s = 0:(n-m)/2 result = result + (-1)^s *factorial(n-s)/ ... (factorial(s)*factorial((n+m)/2 -s)*factorial((n-m)/2-s)) *... r.^(n-2*s); end end

Matlab has incorporated GPU processing on the parallel computing toolbox and you can create GPU array objects using the gpuArray(…) function in MATLAB. I created a brief script to compare matrix multiply of a 2048 x 2048 matrix against a vector. Ordinarily, the CPU operations see reasonable speedup (~2x) from moving from double to single precision values. However, moving to the GPU implementation results in a speedup of 6.8x for Double and 5.6x for Single! This means that if you can take a matrix-vector multiply that is double precision and convert it to single precision GPU version, you may see a gain of nearly 14x.
The following we generated in Matlab R2014b on an i7-4770 3.5 Ghz CPU (8 CPUs) with 16GB Ram and a Geforce GTX 750.
 The next step is to evaluate speed of the gpuArray on a basic L1 Optimization set—l1 magic.
The next step is to evaluate speed of the gpuArray on a basic L1 Optimization set—l1 magic.
The code used to generate this data is as follows:
allTypes = {'Double', 'gpuArrayDouble', 'Single', 'gpuArraySingle'};
allTimes = nan(length(allTypes),1);
n = 2048; % size of operation for Ax
num_mc = 2^10; % number monte carlo runs to compute time average of runs
randn('seed', 1982);
Am = randn(n,n);
xm = randn(n,1);
for ind_type = 1:length(allTypes)
myType = allTypes{ind_type};
switch lower(myType)
case 'double'
A = double(Am);
x = double(xm);
case 'single'
A = single(Am);
x = single(xm);
case 'gpuarraydouble'
A = gpuArray(Am);
x = gpuArray(xm);
case 'gpuarraysingle'
A = gpuArray(single(Am));
x = gpuArray(single(xm));
otherwise
error('Unknown type');
end
tic
for ind_mc = 1:num_mc
y = A*x;
end
allTimes(ind_type) = toc/num_mc;
end
%% Display the results
figure(34);
clf;
bar(allTimes*1000);
set(gca, 'xticklabel', allTypes, 'color', [1 1 1]*.97);
title(['Timing of CPU and GPU in M' version('-release')]);
xlabel('Type');
ylabel('Time (ms)');
grid on
%%
figure(35);
clf;
speedupLabels = {('Double to Single') , ...
('Double to gpuDouble'), ...
('Single to gpuSingle'), ...
'Double to gpuSingle'};
bar([allTimes(1)/allTimes(3), allTimes(1)/allTimes(2), ...
allTimes(3)/allTimes(4), allTimes(1)/allTimes(4)]);
set(gca, 'xticklabelrotation', 15, 'xticklabel', speedupLabels, 'color', [1 1 1]*.97);
title(['Speedup of CPU and GPU in M' version('-release')]);
xlabel('Type');
ylabel('Speedup');
grid on
The Cholesky decomposition takes a Hermitian, positive definite matrix and expresses it as UU’—a highly efficient decomposition for solving system of equations.
We want to decompose the Hermitian positive definite \(A\) into an upper triangular matrix \(U\) such that \(A=U^HU\). Then we can write
\[A=U^HU = \begin{pmatrix} \alpha_{11} & a_{12} \\ a_{12}^H & A_{2,2} \end{pmatrix} = \begin{pmatrix} \bar{\upsilon}_{11} & 0 \\ u_{12}^H & U_{22}^H \end{pmatrix} \begin{pmatrix} \upsilon_{11} & u_{12} \\ 0 & U_{22} \end{pmatrix}\]
and thus
\[ A = \begin{pmatrix} \left| \upsilon_{11} \right| ^2 & \bar{\upsilon}_{11}u_{12} \\ \upsilon_{11} u_{12}^H & u_{12}^H u_{12} + U_{22}^H U_{22} \end{pmatrix} \]
we can solve for the components to get
\[\upsilon_{11} = \sqrt{\alpha_{11}}\]\[u_{12} = a_{12} / \upsilon_{11} \]\[S_{22} = A_{22} – u_{12}^Hu_{12}\]
where \(S_{22}\) is the Schur Complement.
The function chol(…) in MATLAB will create the Cholesky decomposition but their implementation is hidden. A custom implementation is as follows:
function U = chol_sec(A)
if(isempty(A))
U = [];
return;
end;
U = zeros(size(A));
u11 = A(1,1)^(1/2);
u12 = A(1,2:end)/u11;
U(1,1) = u11;
U(1,2:end) = u12;
S22 = A(2:end, 2:end) - u12'*u12;
U(2:end, 2:end) = chol_sec(S22);
end
This code can be exercised using the following:
% Make a test matrix:
randn('seed', 1982);
A = randn(6);% + randn(6)*i;
A= A'*A; % Make it symmetric
% Do the thing:
disp('My Result:');
U = chol_sec(A)
% And run the matlab intrinsic to be sure we got the right result:
disp('MATLAB''s Result');
U_matlab = chol(A)
err = norm(U - U_matlab)
Also, a MATLAB tends to die with large dimensions because the recursion depth is limited. To avoid this you can use a non-recursive formulation as follows:
function U = chol_nr_sec(A)
U = zeros(size(A));
for n = 1:length(A)
u11 = A(n,n)^(1/2);
u12 = A(n,(1+n):end)/u11;
U(n,n) = u11;
U(n,(1+n):end) = u12;
A((n+1):end, (n+1):end) = A((n+1):end, (n+1):end) - u12'*u12;
end
end
The non-recursive formulation is about 33% faster than the recursive formulation on my system with MATLAB 2013a, but is about 200 times slower than the intrinsic formulation.