Example Path: %NVCUDASAMPLES_ROOT%\1_Utilities\bandwidthTest
The NVIDIA CUDA Example Bandwidth test is a utility for measuring the memory bandwidth between the CPU and GPU and between addresses in the GPU.
The basic execution looks like the following:
[CUDA Bandwidth Test] - Starting... Running on... Device 0: GeForce GT 650M Quick Mode Host to Device Bandwidth, 1 Device(s) PINNED Memory Transfers Transfer Size (Bytes) Bandwidth(MB/s) 33554432 6286.1 Device to Host Bandwidth, 1 Device(s) PINNED Memory Transfers Transfer Size (Bytes) Bandwidth(MB/s) 33554432 6315.7 Device to Device Bandwidth, 1 Device(s) PINNED Memory Transfers Transfer Size (Bytes) Bandwidth(MB/s) 33554432 44976.7 Result = PASS
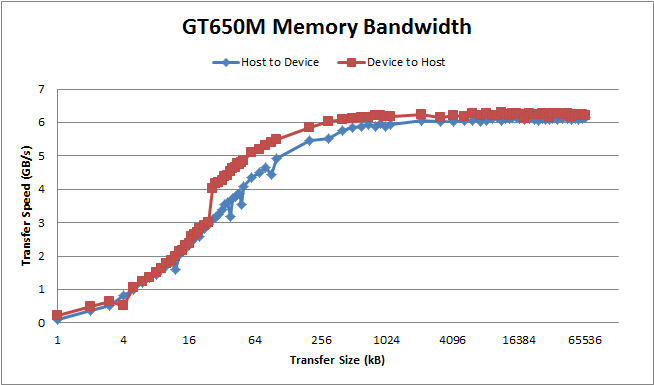
This was run on an NVIDIA Geforce GT 650M 1GB Mobile graphics card from a laptop. The device to host memory transfers are about 6GB/s while transfers inside the card occur at ~50GB/s. The transfer from host to device and device to host is often symmetric. However, I have seen systems exhibit non-symmetric transfers—such as on a PC104 architecture. Also, more bandwidth can be achieved in by using more address lines. That is, if you are using PCIe x4 or x8 or x16. And some motherboards currently have x16 physical connectors but only x8 electrical. The pinned memory is faster than simple pageable memory, in this case about 50% as pageable is only 4GB/s on host<->device transfers. There are a number of options you can pass. To see more use the –help flag when running the executable.
In the code there is a fair amount of command line parsing and generic testBandwidthRange but the real work is in testDeviceToHostTransfer, testHostToDeviceTransfer, and testDeviceToDeviceTransfer. In any case, the host memory is allocated using malloc(memSize) for pageable memory or cudaHostAlloc(…) for pinned memory (for fast transfer). The desired transfer is then done 10 times in a row and the total time is recorded with an event in the stream. If the memory is pinned then is uses asynchronous memory transfers and standard memory transfers otherwise:
checkCudaErrors(cudaEventRecord(start, 0));
//copy host memory to device memory
if (PINNED == memMode)
{
for (unsigned int i = 0; i < MEMCOPY_ITERATIONS; i++)
{
checkCudaErrors(cudaMemcpyAsync(d_idata, h_odata, memSize,
cudaMemcpyHostToDevice, 0));
}
}
else
{
for (unsigned int i = 0; i < MEMCOPY_ITERATIONS; i++)
{
checkCudaErrors(cudaMemcpy(d_idata, h_odata, memSize,
cudaMemcpyHostToDevice));
}
}
checkCudaErrors(cudaEventRecord(stop, 0));
The total bandwidth found is dependent on the size of the transfer. Each transfer has a certain amount of overhead that will drag transfers down if you attempt to perform small transfers instead of a few large ones. The effect largely disappears for transfers larger than 256kB, though.